
A machine learning algorithm is a method by which the AI system conducts its task, generally predicting output values from given input data. The two main processes of machine learning algorithms are classification and regression.
What is Machine learning?
Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy. The term “machine learning” was coined by Arthur Samuel, a computer scientist at IBM and a pioneer in AI and computer gaming. Samuel designed a computer program for playing checkers. The more the program played, the more it learned from experience, using algorithms to make predictions
While machine learning is based on the idea that machines should be able to learn and adapt through experience, AI refers to a broader idea where machines can execute tasks “smartly.” Artificial Intelligence applies machine learning, deep learning and other techniques to solve actual problems. Machine learning is used in internet search engines, email filters to sort out spam, websites to make personalised recommendations, banking software to detect unusual transactions, and lots of apps on our phones such as voice recognition.
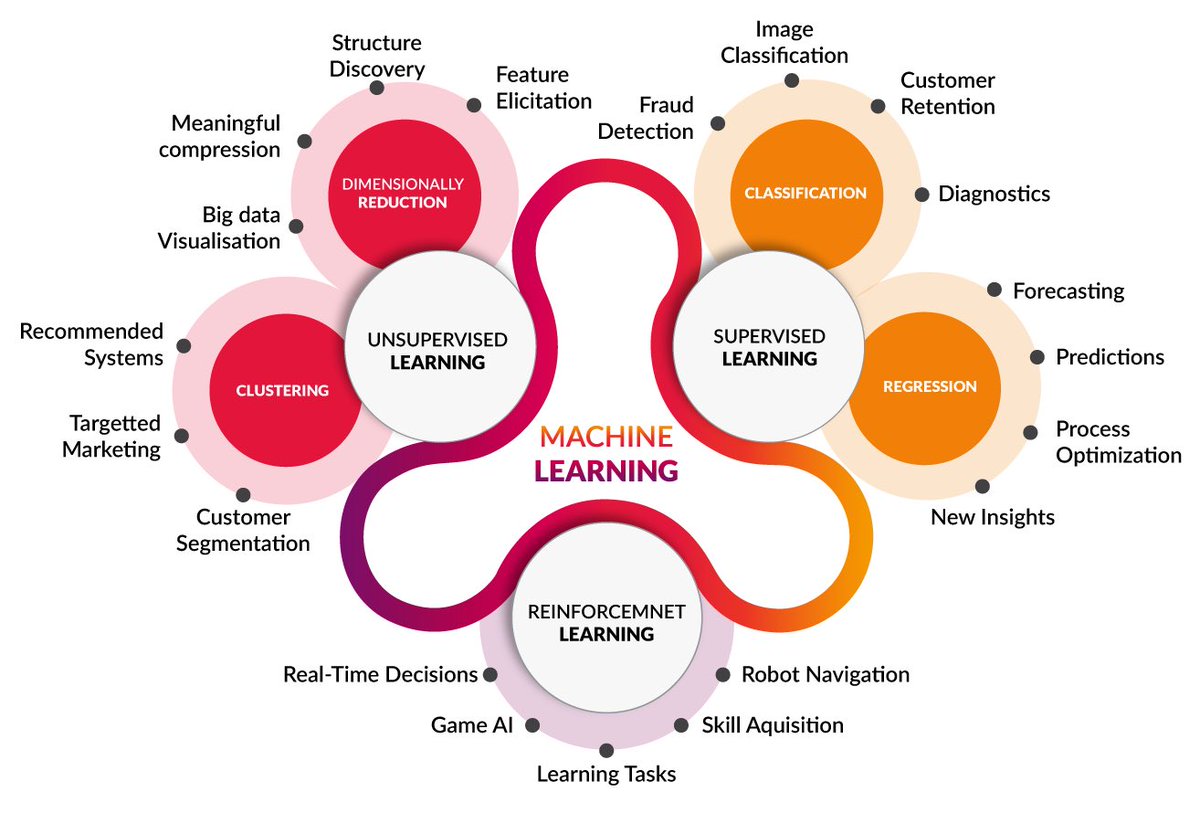
There are three machine learning types: supervised, unsupervised, and reinforcement learning
- Supervised Learning predicts based on a class type. A supervised learning algorithm takes labelled data and creates a model that can make predictions given new data. This can be either a classification problem or a regression problem. Supervised learning is, thus, best suited to problems where there is a set of available reference points or a ground truth with which to train the algorithm. But those aren’t always available.
- Unsupervised Learning discovers underlying patterns. Unsupervised learning is when we are dealing with data that has not been labelled or categorized. The goal is to find patterns and create structure in data in order to derive meaning. Two forms of unsupervised learning are clustering and dimensionality reduction.
- Reinforcement Learning, the learning agent works as a reward and action system. Reinforcement learning operates on the same principle — and actually, video games are a common test environment for this kind of research. In this kind of machine learning, AI agents are attempting to find the optimal way to accomplish a particular goal or improve performance on a specific task. As the agent takes action that goes toward the goal, it receives a reward. The overall aim: predict the best next step to take to earn the biggest final reward.
What’s Python?
Python is a high-level, interpreted, general-purpose programming language. Its design philosophy emphasizes code readability with the use of significant indentation. Python is dynamically-typed and garbage-collected. It supports multiple programming paradigms, including structured (particularly procedural), object-oriented and functional programming. It is often described as a “batteries included” language due to its comprehensive standard library.
Python has become one of the most popular programming languages in the world in recent years. It’s used in everything from machine learning to building websites and software testing. It can be used by developers and non-developers alike. Python is commonly used for developing websites and software, task automation, data analysis, and data visualization. Since it’s relatively easy to learn, Python has been adopted by many non-programmers such as accountants and scientists, for a variety of everyday tasks, like organizing finances.
Python has become a staple in data science, allowing data analysts and other professionals to use the language to conduct complex statistical calculations, create data visualizations, build machine learning algorithms, manipulate and analyze data, and complete other data-related tasks. Python can build a wide range of different data visualizations, like line and bar graphs, pie charts, histograms, and 3D plots. Python also has a number of libraries that enable coders to write programs for data analysis and machine learning more quickly and efficiently, like TensorFlow and Keras.
Do you love Machine Learning? Check out “Defining the Differences between MLOps, ModelOps, DataOps & AIOps“
8 Machine Learning Algorithms in Python
Machine learning algorithms are a set of instructions for a computer on how to interact with, manipulate, and transform data. There are so many types of machine learning algorithms. Selecting the right algorithm is both science and art.
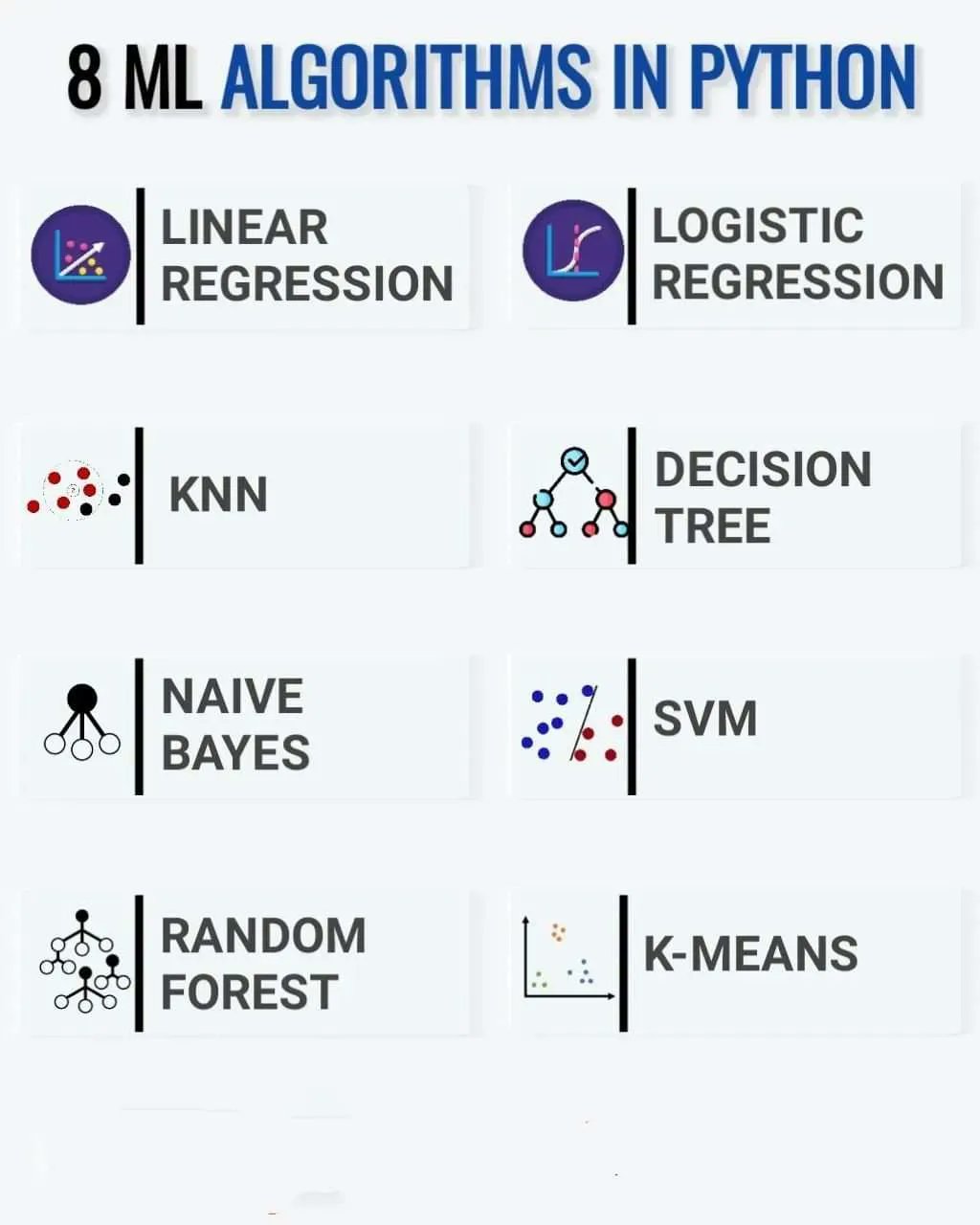
- Linear Regression analysis is used to predict the value of a variable based on the value of another variable. The variable you want to predict is called the dependent variable. The variable you are using to predict the other variable’s value is called the independent variable.
- K-NN is a non-parametric algorithm, which means it does not make any assumptions on underlying data. It is also called a lazy learner algorithm because it does not learn from the training set immediately instead it stores the dataset and at the time of classification, it performs an action on the dataset.
- The Naive Bayes classification algorithm is a probabilistic classifier. It is based on probability models that incorporate strong independence assumptions. The independence assumptions often do not have an impact on reality. Therefore they are considered naive.
- Random forest is a Supervised Machine Learning Algorithm that is used widely in Classification and Regression problems. It builds decision trees on different samples and takes their majority vote for classification and average in case of regression.
- Logistic regression is a supervised learning classification algorithm used to predict the probability of a target variable. The nature of the target or dependent variable is dichotomous, which means there would be only two possible classes.
- Decision trees use multiple algorithms to decide to split a node into two or more sub-nodes. The creation of sub-nodes increases the homogeneity of resultant sub-nodes. In other words, we can say that the purity of the node increases with respect to the target variable.
- Support Vector Machine(SVM) is a supervised machine learning algorithm used for both classification and regression. Though we say regression problems as well its best suited for classification. The objective of SVM algorithm is to find a hyperplane in an N-dimensional space that distinctly classifies the data points.
- k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster.

Machine Learning with Scikit-Learn
Scikit-learn is a library in Python that provides many unsupervised and supervised learning algorithms. It’s built upon some of the technology you might already be familiar with, like NumPy, pandas, and Matplotlib!

The functionality that scikit-learn provides include:
- Regression, including Linear and Logistic Regression
- Classification, including K-Nearest Neighbors
- Clustering, including K-Means and K-Means++
- Model selection
- Preprocessing, including Min-Max Normalization

References
https://www.techtarget.com/whatis/definition/machine-learning-algorithm
https://www.ibm.com/in-en/cloud/learn/machine-learning
https://www.coursera.org/articles/what-is-python-used-for-a-beginners-guide-to-using-python
https://www.kaggle.com/code/marcovasquez/top-machine-learning-algorithms-beginner/notebook



